In dieser Reihe stellen wir digitale Hilfsmittel vor, die für die Arbeit an der Universität Erfurt nützlich sein können – für die Forschung, kollaboratives Arbeiten oder die (Selbst)Organisation. Bei Fragen rund um diese Themen steht Ihnen die Koordinatorin für Digital Humanities der Universität Erfurt zur Verfügung, deren Büro in der Universitätsbibliothek angesiedelt ist (https://www.uni-erfurt.de/bibliothek/forschungsunterstuetzende-dienste/digital-humanities/).
Heute geht es um
OpenRefine
– ein interaktives Tool zur Bereinigung und Aufbereitung größerer Mengen von Daten. Die Open-Source-Software bietet zahlreiche Möglichkeiten, die größtenteils ohne weitere Programmierkenntnisse in einer tabellenartigen Benutzeroberfläche ausgeführt werden können. Diese hat mit Zeilen und Spalten große Ähnlichkeiten mit Excel-Tabellen (ein „OpenRefine-Projekt“ = eine Tabelle) und stellt verschiedene Arten von Filtern und Facetten zur Verfügung. Das Tool läuft im Browser (auch ohne Internetverbindung) lokal auf dem Rechner.
In OpenRefine können u.a. die Datenformate TSV, CSV, Excel, JSON, XML und RDF verarbeitet werden, außerdem können SQL-Exporte erstellt werden, um die Daten in einer Datenbank weiterzubearbeiten bzw. auszuwerten. Darüber hinaus bietet das Tool die Möglichkeit, die eigenen Daten mit anderen Datenquellen abzugleichen, anzureichern und zu verlinken, z.B. mit Wikidata oder mit der Gemeinsamen Normdatei (GND).
Durch die Arbeit mit OpenRefine bekommt man ein neues Gespür für seine Daten („Exploration“), kann mit ihnen spielen, Inkonsistenzen oder Fehler entdecken.
Hier ein Beispiel für eine Anwendung: Aus einem großen Datenset
- werden alle leeren Suchanfragen gelöscht
- werden Leerzeichen am Anfang und Ende der Sucheingabe gelöscht
- wird der gesamte Text in Kleinbuchstaben umgewandelt.
Alle Operationen geschehen in der Regel nur mit den selektierten Daten. Veränderungen basieren auf einer Kopie des Datensets, so dass sie leicht rückgängig gemacht werden können, Operationsabfolgen können gespeichert und auf andere Datensätze angewendet werden.
OpenRefine ist ein Tool, das bei der Konsolidierung und Transformation von Daten Arbeitsschritte vereinfacht oder bei größeren Datenmengen überhaupt erst ermöglicht.
https://librarycarpentry.org/lc-open-refine/
https://histhub.ch/histhub-lab-tutorials-zu-openrefine/
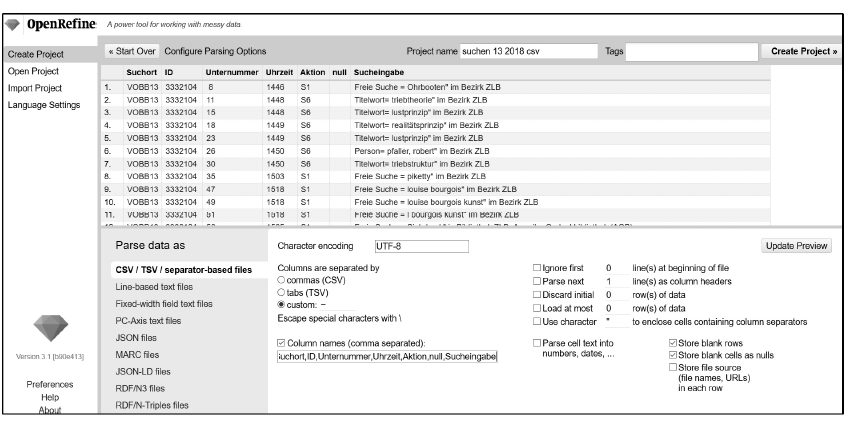
Screenshot aus der bisher unpublizierten Abschlussarbeit von Dr. Verena Feistauer im Rahmen der Laufbahnprüfung für Bibliotheksreferendarinnen und Bibliotheksreferendare am Institut für Bibliotheks- und Informationswissenschaft der Humboldt-Universität zu Berlin: „Wie suchen Nutzer*innen wirklich? Eine Analyse der Suchanfragen im Verbund der Öffentlichen Bibliotheken Berlins (VÖBB)“, S. 10, Abb. 1.